
Pengertian Image Captioning (Caption Generation), Apa itu? Tujuan, Cara Kerja, Jenis Arsitektur, Macam Dataset, dan Contoh Cara Implementasinya dengan Deep Learning!
Seperti yang kita ketahui saat ini, pembelajaran mendalam (deep learning) dan pembelajaran mesin (machine learning) adalah teknologi (baca apa maksud dan pengertian teknologi di sini) paling progresif di era ini, khususnya di tahun 2026 sekarang.
Artificial Intelligence (AI) atau Kecerdasan buatan sekarang dibandingkan dengan pikiran manusia dan di beberapa bidang AI melakukan pekerjaan yang lebih baik daripada manusia dari waktu ke waktu.
Benar! Hari demi hari ada penelitian baru bermunculan di bidang ini, salah satunya adalah image caption generation.
Bidang ini meningkat sangat cepat karena sekarang kita sudah memiliki kekuatan komputasi (terkait hardware) yang cukup untuk melakukan task atau tugas deep learning (pembelajaran mendalam) yang merupakan cabang pembelajaran mesin dan turunan utama dari data science (lihat pengertian data science di sini) yang menggunakan jaringan saraf dengan banyak layer atau lapisannya.
Baiklah, berdasarkan hal tersebutlah, dalam postingan kali ini Kami akan membahas pengertian image captioning secara detail dan lengkap.
Mari kita simak berikut di bawah ini!
Daftar Isi Konten:
- Pengertian Image Captioning
- Apa itu Image Captioning, Caption Generation, Generator, atau Keterangan Gambar Otomatis?
- Tujuan dan Fungsi Image Captioning
- Cara Kerja dan Ide Image Captioning
- Jenis Macam Arsitektur dan Dataset dalam Image Captioning, Caption Generation, Generator, atau Keterangan Gambar Otomatis
- Bagaimana Contoh dan Implementasi Image Caption Generation, Generator, atau Keterangan Gambar Otomatis dalam Deep Learning
- Kesimpulan
- Penutup
Pengertian Image Captioning
Berarti keterangan gambar otomatis dan juga dikenal dengan sebutan caption generation, generator, image captioning adalah proses menghasilkan deskripsi tekstual dari sebuah foto atau gambar dengan metode klasifikasi gambar dan teks otomatis yang merupakan gabungan dari subbidang dalam ilmu data.
Teknik berbasis deep learning ini mencakup pemrosesan bahasa alami atau Natural Language Processing (NLP) dan visi komputer atau Computer Vision (CV) untuk menghasilkan teks daengan menggunakan algoritma Convolutional Neural Network (CNN).
Mengutip sumber simpulan Kami dari jurnal atau paper berjudul “A Comprehensive Survey of Deep Learning for Image Captioning” oleh dan menurut para pakar dan ahli dengan penulis utama MD. Zakir Hossain, captioning gambar membutuhkan pengenalan objek penting, atribut mereka, dan hubungan mereka dalam sebuah gambar.
Pembuatan keterangan teks otomatis pada gambar tersebut juga perlu menghasilkan kalimat yang benar secara sintaksis dan semantik.
Yup! Seperti yang kalian lihat, teknik berbasis deep-learning mampu menangani kompleksitas dan tantangan teks gambar.
Apa itu Image Captioning, Caption Generation, Generator, atau Keterangan Gambar Otomatis?
Oke, jadi apa itu sebenarnya yang dimaksud dengan image captioning, caption generation, generator, atau keterangan gambar otomatis ini?
Baik, seperti yang sudah Kami terangkan pada pengertian dan arti katanya di atas, ini lebih dikenal dengan sebutan image captioning secara global.
Image captioning, caption generation, generator, atau keterangan gambar otomatis ini secara sederhana merupakan proses menghasilkan deskripsi tekstual untuk gambar yang diberikan.
Beberapa manfaatnya yaitu seperti aplikasi atau implementasi captioning gambar oleh NVIDIA yang menggunakan teknologi teks gambar untuk membuat aplikasi untuk membantu orang yang memiliki penglihatan rendah atau tidak memiliki penglihatan.
Selain itu, manfaat, kegunaan, atau keuntungan image captioning juga termasuk seperti rekomendasi dalam aplikasi pengeditan, penggunaan dalam asisten virtual, untuk pengindeksan gambar, untuk tunanetra, untuk media sosial, dan beberapa aplikasi pemrosesan bahasa alami lainnya.
Beberapa pendekatan telah dilakukan untuk menyelesaikan tugas tersebut, dan salah satu karya paling menonjol telah dikemukakan oleh Andrej Karpathy, Direktur AI., Tesla dalam gelar Ph.D. di Standford.
Selain itu, pada postingan ini kita juga akan melihat contoh demo cara implementasinya dengan menggunakan bahasa pemrograman Python.
Keterangan gambar dapat dianggap sebagai masalah urutan ke urutan ujung ke ujung atau “end-to-end Sequence to Sequence problem” karena mengubah gambar, yang dianggap sebagai urutan piksel menjadi urutan kata.
Benar! Untuk tujuan ini, kita sebagai peneliti atau praktisi perlu memproses bahasa atau pernyataan dan gambar.
Untuk bagian teks atau bahasanya, state-of-the-art ini juga menggunakan berbagai metode, di mana salah satunya yang populer yaitu jaringan neural berulang atau Recurrent Neural Network (RNN) dan untuk bagian image (foto atau gambar), itu menggunakan CNN untuk mendapatkan vektor fitur masing-masingnya.
Tujuan dan Fungsi Image Captioning
Agar kita semua dapat memahami secara lebih lengkap terkait pengertian image captioning, maka selanjutnya kita juga harus mengetahui apa sebenarnya tujuan utama dan fungsi melakukan keterangan gambar otomatis ini.
Oke, perlu Kami tekankan di sini bahwa tujuan utama dari image captioning adalah untuk mengubah gambar masukan yang diberikan menjadi deskripsi bahasa alami.
Ini semua melibatkan konsep visi komputer dan pemrosesan bahasa alami yang berfungsi untuk mengenali konteks gambar dan mendeskripsikannya dalam bahasa alami seperti layaknya ketika seorang manusia memberikan penjelasan bagaimana suatu gambar itu dilihat.
Secara khusus, selain untuk pengembangan algoritma CNN, image captioning juga sangat berguna untuk masalah penglihatan manusia dan komputer.
Cara Kerja dan Ide Image Captioning
Baik, sekarang, kita telah mengetahui apa pengertian dari image captioning, caption generation, generator, atau keterangan gambar otomatis.
Jadi, pertanyaan selanjutnya adalah, bagaimana sebenarnya cara kerja ide image captioning tersebut?
Baik, untuk menjelaskannya, katakanlah, kita sebagai manusia melihat gambar seperti yang Kami sediakan di bawah ini.

Jadi, bagaimana Anda melihat dan menjelaskannya?
Jika kita disuruh mendeskripsikannya, mungkin kita akan menggambarkannya dengan “Seekor Jerapah di padang rumput”.
Lalu, bagaimana kita melakukan ini dengan menggunakan mesin, khususnya komputer?
Saat membentuk deskripsi, kita semua melihat gambar tetapi pada saat yang sama, kita mencari untuk membuat rangkaian kata yang bermakna.
Benar! Pada umumnya, untuk bagian pertamanya, metode tersebut ditangani oleh CNN sebagai encode dan yang kedua ditangani oleh RNN (disebut LSTM dan implementasi lainnya juga bisa menggunakan berbagai arsitektur seperti Transformer) sebagai decoder.
Jika kita dapat memperoleh kumpulan data yang sesuai dengan gambar dan deskripsi manusia yang sesuai, maka kita dapat melatih jaringan untuk memberi teks gambar secara otomatis.
Flickr dan MS-COCO adalah beberapa kumpulan data yang paling sering digunakan untuk tujuan tersebut (akan kita bahas pada subbagian jenis dan macam dataset-nya selanjutnya).
Sekarang, satu masalah lain yang mungkin kita abaikan di sini, di mana kita telah melihat bahwa kita dapat menggambarkan gambar di atas dalam beberapa cara.
Jadi, bagaimana kita mengevaluasi atau mengetahui tingkat akurasi, kebenaran, atau seberapa valid metode atau model tersebut?
Untuk masalah urutan ke urutan, seperti ringkasan, terjemahan bahasa, atau teks, maka kita menggunakan Metrik yang disebut skor BLEU.
BLEU adalah singkatan dari Bilingual Evaluation Understudy.
Ini adalah metrik untuk mengevaluasi kalimat yang dihasilkan ke kalimat referensi, di mana kecocokan sempurnanya adalah 1,0 dan ketidakcocokan sempurnanya adalah 0,0.
Di sini, kita telah melihat bahwa kita perlu membuat jaringan saraf multimodal yang menggunakan vektor fitur yang diperoleh, sehingga, di sini ide tersebut bekerja dengan memiliki dua input.
Ya, begitulah secara umum terkait bagaimana cara kerjanya, di mana secara umum kalian dapat melihatnya melalui gambar alur metode yang terdapat pada jurnal “Show, Attend and Tell Neural image Caption Generation with Visual Attention” di bawah.
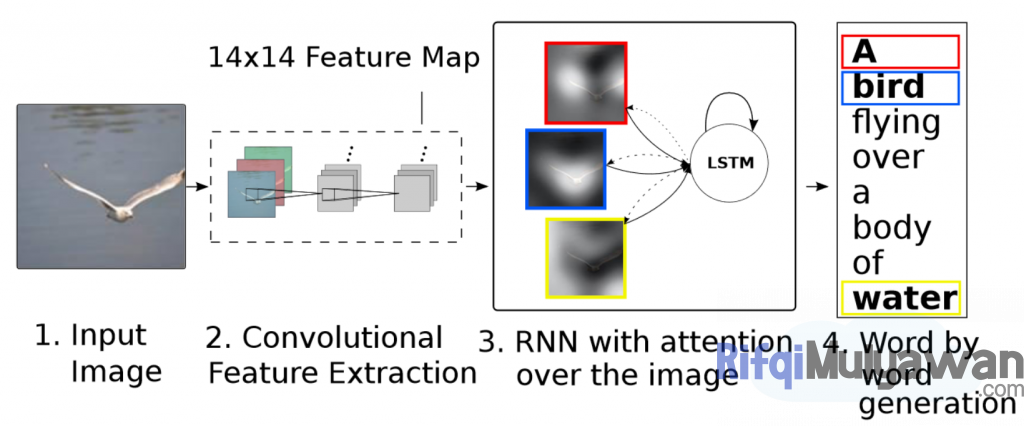
Jenis Macam Arsitektur dan Dataset dalam Image Captioning, Caption Generation, Generator, atau Keterangan Gambar Otomatis
Dalam membahas tentang pengertian image captioning, kita juga perlu untuk mengetahui apa saja jenis dan macam arsitektur yang terdapat di dalam prosesnya.
Adapun beberapa jenis arsitektur yang digunakan dalam masalah image captioning adalah sebagai berikut:
- Inject Architecture; Arsitektur injeksi ini menggabungkan bentuk gambar yang dikodekan dengan setiap kata dari deskripsi teks yang dihasilkan sejauh ini. Pendekatan ini menggunakan jaringan saraf tiruan sebagai model generasi teks yang menggunakan urutan informasi gambar dan kata sebagai input untuk menghasilkan kata berikutnya dalam urutan.
- Merge Architecture; Arsitektur merge atau penggabungan ini menggabungkan kedua bentuk input gambar yang dikodekan dengan bentuk deskripsi teks yang dikodekan yang dihasilkan. Kombinasi dari dua input yang dikodekan ini kemudian digunakan oleh model dekoder yang sangat sederhana untuk menghasilkan kata berikutnya dalam urutan.
Lalu, untuk macam-macam dataset (kumpulan data) yang seringkali digunakan untuk proses penelitian dan pengembangannya yaitu:
- Common Objects in Context (COCO) versi 14, 15, dan 17; Koleksi lebih dari 120 (seratus dua puluh) ribu gambar dengan deskripsi.
- Flickr 8K; Kumpulan 8 (delapan) ribu gambar yang dijelaskan diambil dari flickr.com.
- Flickr 30K; Kumpulan 30 (tiga puluh) ribu gambar yang dijelaskan diambil dari flickr.com.
- Nocaps; Benchmark nocaps terdiri dari 166.100 (seratus enam puluh ribu seratus) teks buatan manusia yang menjelaskan 15.100 (lima belas ribu seratus) gambar dari validasi OpenImages dan set pengujian.
Bagaimana Contoh dan Implementasi Image Caption Generation, Generator, atau Keterangan Gambar Otomatis dalam Deep Learning

Baik, sekarang bagaimana contoh dan cara implementasinya dalam deep learning?
Mari kita lihat implementasi sederhana dari image captioning di Pytorch (library untuk pemelajaran mesin open source yang dibuat berdasarkan pustaka Torch).
Di sini Kami akan mengambil sebuah gambar sebagai input, dan memprediksi deskripsinya menggunakan model deep learning.
Kode untuk contoh ini dapat kalian salin secara langsung, dan untuk kreditnya, bisa kalian cari di Github akun pengguna Yunjey Choi.
Dalam panduan ini, model bernama Resnet-152 yang telah dilatih sebelumnya (pre-trained) digunakan sebagai encoder, dan decoder-nya adalah jaringan atau LSTM networks.
Untuk menjalankan kode yang diberikan dalam contoh ini, Anda harus menginstal prasyarat atau requirements-nya tentunya.
Jadi, pastikan Anda memiliki lingkungan atau environment Python yang berfungsi, dan saran Kami sebaiknya dengan menginstall aplikasi Anaconda, khususnya jika kalian menggunakan Windows.
Untuk memulainya, jalankan perintah berikut untuk menginstal sisa perpustakaan yang diperlukan.
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI/
make
python setup.py build
python setup.py install
cd ../../Code language: PHP (php)Setelah Anda menyiapkan sistem, Anda harus mengunduh kumpulan data yang diperlukan untuk melatih modelnya.
Di sini kita akan menggunakan dataset MS-COCO.
Untuk mendownload dataset secara otomatis, Anda dapat menjalankan perintah berikut:
chmod +x download.sh
./download.shSekarang Anda dapat melanjutkan dan memulai proses pembuatan model Anda.
Mulailah dengan memproses input atau masukannya:
#Cari semua kemungkinan kata dalam dataset dan
#Membangun daftar kosa kata
python build_vocab.py
#Resize semua gambar untuk membuatnya berbentuk 224x224
python resize.pyCode language: CSS (css)Sekarang Anda dapat mulai melatih atau melakukan training pada model Anda dengan menjalankan perintah di bawah ini:
python train.py --num_epochs 10 --learning_rate 0.01Code language: CSS (css)Untuk melihat bagaimana kita mendefinisikan modelnya, Anda dapat merujuk ke kode yang ditulis dalam file model.py yang dapat kalian lihat di bawah ini.
import torch
import torch.nn as nn
import torchvision.models as models
from torch.nn.utils.rnn import pack_padded_sequence
from torch.autograd import Variable
class EncoderCNN(nn.Module):
def __init__(self, embed_size):
"""Memuat ResNet-152 dan mengganti layer fc atas."""
super(EncoderCNN, self).__init__()
resnet = models.resnet152(pretrained=True)
modules = list(resnet.children())[:-1] # delete the last fc layer.
self.resnet = nn.Sequential(*modules)
self.linear = nn.Linear(resnet.fc.in_features, embed_size)
self.bn = nn.BatchNorm1d(embed_size, momentum=0.01)
self.init_weights()
def init_weights(self):
"""Menginisialisasi weights."""
self.linear.weight.data.normal_(0.0, 0.02)
self.linear.bias.data.fill_(0)
def forward(self, images):
"""Melakukan ekstraksi vektor fitur gambar."""
features = self.resnet(images)
features = Variable(features.data)
features = features.view(features.size(0), -1)
features = self.bn(self.linear(features))
return features
class DecoderRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers):
"""Set the hyper-parameters and build the layers."""
super(DecoderRNN, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, vocab_size)
self.init_weights()
def init_weights(self):
"""Inisialisasi weights."""
self.embed.weight.data.uniform_(-0.1, 0.1)
self.linear.weight.data.uniform_(-0.1, 0.1)
self.linear.bias.data.fill_(0)
def forward(self, features, captions, lengths):
"""Melakukan proses decode fitur vektor gambar dan generate keterangan gambar."""
embeddings = self.embed(captions)
embeddings = torch.cat((features.unsqueeze(1), embeddings), 1)
packed = pack_padded_sequence(embeddings, lengths, batch_first=True)
hiddens, _ = self.lstm(packed)
outputs = self.linear(hiddens[0])
return outputs
def sample(self, features, states=None):
"""Contoh captions untuk fitur gambar yang diberikan (Greedy Search)."""
sampled_ids = []
inputs = features.unsqueeze(1)
for i in range(20): # maximum sampling length
hiddens, states = self.lstm(inputs, states) # (batch_size, 1, hidden_size),
outputs = self.linear(hiddens.squeeze(1)) # (batch_size, vocab_size)
predicted = outputs.max(1)[1]
sampled_ids.append(predicted)
inputs = self.embed(predicted)
inputs = inputs.unsqueeze(1) # (batch_size, 1, embed_size)
sampled_ids = torch.cat(sampled_ids, 1) # (batch_size, 20)
return sampled_ids.squeeze()Oke, sekarang kita dapat menguji model kita menggunakan gambar secara langsung:
python sample.py --image='png/contoh.png'Code language: JavaScript (javascript)Untuk contoh gambar kali ini, model tersebut akan menampilkan output atau hasil seperti ini:

Selesai, kita telah berhasil mempraktikkan dan mengimplementasikan ide image captioning sederhana.
Untuk lebih lanjutnya, kalian dapat mencari jurnal terkait, atau silahkan kalian coba akses situs seperti Machine Learning Mastery atau Toward Data Science.
Kesimpulan
Oke, Kami pikir sudah cukup diterangkan sekarang untuk Pengertian Image Captioning (Caption Generation), Apa itu? Tujuan, Cara Kerja, Jenis Arsitektur, Macam Dataset, Contoh Cara Implementasinya dengan Deep Learning.
Jadi, berdasarkan penjelasan di atas, dapat kita simpulkan bahwa image captioning, caption generation, generator, atau keterangan gambar otomatis adalah tugas mendeskripsikan isi sebuah gambar dengan kata-kata.
Tugas ini terletak di persimpangan visi komputer dan pemrosesan bahasa alami dan sebagian besar sistem teks gambar menggunakan kerangka kerja encoder–decoder, di mana gambar input dikodekan menjadi representasi perantara dari informasi dalam gambar, dan kemudian diterjemahkan ke dalam urutan teks deskriptif.
Adapun untuk tolak ukur yang paling populer adalah Nocaps dan COCO, dan model biasanya dievaluasi menurut metrik BLEU atau CIDER.
Beberapa contoh penelitian terbaru dalam masalah ini yaitu adalah pendekatan dengan menggunakan model Transformer (language model) yang diterapkan pada berbagai macam bahasa, di mana salah satunya adalah paper Image Captioning berjudul “Automatic Indonesian Image Captioning using CNN and Transformer-Based Model Approach” yang telah terbit, terindek di IEEE Explore (juga terindeks Scopus).
Yup! Alat Image Captioning berbasis AI menghasilkan teks yang dapat dibaca manusia atau deskripsi tekstual setelah memahami gambar berdasarkan komponen individu dari objek dan tindakan yang diambil di dalamnya.
Penutup
Demikianlah postingan artikel yang dapat Kami bagikan kali ini, di mana Kami membahas terkait Pengertian Image Captioning (Caption Generation), Apa itu? Tujuan, Cara Kerja, Jenis Arsitektur, Macam Dataset, dan Contoh Cara Implementasinya dengan Deep Learning.
Semoga apa yang sudah Kami coba sampaikan serta jelaskan di sini dapat bermanfaat dan juga dapat menambah wawasan dan pengetahuan kita semua terutama dalam bidang terkait teknologi, khususnya Computer Vision (CV), Natural Language Processing (NLP), dan deep learning.
Silahkan bagikan artikel atau postingan Kami di sini kepada teman, kerabat serta rekan kerja dan bisnis kalian semua khususnya jika kalian temukan ini bermanfaat dan juga jangan lupa subscribe Blog dan YouTube Kami. Sekian dari Kami, Terima Kasih.
Postingan ini juga tersedia dalam versi:





 di HP/Smartphone/Mobile: Pengertian, Jenis, Macam-Macam Peran, Tantangan, serta Masa Depan Implementasi dan Inovasinya!")


