
Makalah tentang Data Science, Ringkasan, Teori, Contoh Kasus, Perhitungan, Lengkap + Link Downloadnya!
Baiklah, seperti yang sudah Kami bahas dalam beberapa postingan sebelumnya, yang berjudul pengertian data science, ilmu data, ini dapat dikatakan sebagai teknologi yang berada di balik penanganan dan pengerjaan data di abad ke-2x (tahun 2026) sekarang ini.
Benar! Konsepnya telah terbukti menjadi puncak dalam beberapa tahun terakhir dengan munculnya Artificial Intelligence dan Deep Learning.
Khusus teman-teman dan agan-agan yang kebetulan sedang menjalani perkuliahan khususnya tentang mata kuliah ilmu data, dalam postingan kali ini Kami akan membagikan materi ringkasan dari berbagai sumber terpercaya yang ada dalam buku beberapa professor, pakar, ahli dan di internet yang sudah Kami kumpulkan agar lebih kalian mengerti dalam memahaminya.
Oke baiklah langsung saja, berikut ini adalah makalah atau ringkasan tentang data science termasuk teori, contoh kasus beserta dengan cara perhitungannya secara lengkap.
Daftar Isi Konten:
- Sekilas tentang Data Science (Ilmu Data)
- Mengenal Business Analytics dan Data Analytic dalam Data Science
- Apa itu Data, Informasi, dan Pengetahuan?
- Statistika Deskriptif dalam Data Science
- Apa Perbedaan Data Science dengan Artificial Intelligence (AI)?
- Apa Perbedaan Data Mining dengan Machine Learning?
- Data Science dan Algoritma Klasifikasi
- Deep Learning dan Data Science
- Metode Regresi dan Regresi Linier
- Algoritma Clustering dan K-Means Clustering
- Algoritma Association Rule dan Apriori
- Daftar Pustaka
- Kesimpulan
- Penutup
Sekilas tentang Data Science (Ilmu Data)
Kemajuan teknologi dan perubahan terkait dalam kehidupan praktis sehari-hari telah menghasilkan perkembangan yang pesat dunia parallel konten baru, data baru, dan sumber informasi baru di sekitar kita.
Terlepas dari bagaimana seseorang mendefinisikannya, fenomena atau istilah big data semakin hadir, semakin meresap, dan semakin penting.
Di sana adalah potensi nilai yang sangat besar dalam istilah yang kita kenal dengan big data termasuk seperti wawasan inovatif, pemahaman yang lebih baik tentang masalah, dan banyak lagi hal-hal lainnya.
Itu juga dapat memberi peluang untuk memprediksi, dan bahkan untuk membentuk masa depan itu sendiri.
Secara umum, data science adalah sarana utama untuk menemukan dan menekankan akan potensi itu, istilah yang berarti ilmu data dalam bahasa indonesia ini menyediakan cara untuk menangani dan memanfaatkan kumpulan data besar untuk melihat pola, untuk menemukan relasi serta untuk memahami berbagai gambar dan informasi yang memukau.
Tidak semua orang telah mempelajari analisis statistik secara mendalam, dan juga orang-orang yang memiliki gelar lanjutan dalam matematika terapan bukanlah komuditasnya.
Di luar sana, terbilang cukup sedikit organisasi yang menggunakan sumber daya untuk kumpulan data yang besar, di mana itu dikumpulkan terutama untuk tujuan analisis eksplorasi.
Namun, saat menerapkan praktik data science, khususnya untuk big data dapat menjadi strategi pembeda yang berharga saat ini, terlebih itu akan menjadi kompetensi inti standar dalam waktu singkat.
Mengenal Business Analytics dan Data Analytic dalam Data Science
Business analytics secara bahasa berarti analisis bisnis, ini adalah serangkaian praktik, alat, dan layanan analisis data otomatis yang membantu kita memahami apa yang terjadi dalam bisnis dan alasannya, untuk meningkatkan pengambilan keputusan dan membantu merencanakan masa depan.
Adapun contoh dari business analytics dan penerapannya ini yaitu seperti perusahaan pemesanan makanan online menginginkan wawasan baru yang dapat meningkatkan produktivitas dan merampingkan operasi komersial.
Perusahaan tersebut menerapkan dasbor yang memberikan akses waktu nyata ke siklus hidup pelanggannya, di mana ini menghasilkan data yang memfasilitasi perampingan kegiatan penjualan dan kampanye pemasaran, sehingga mencapai tujuan untuk meningkatkan produktivitas.
Istilah business analytics ini juga sering digunakan dalam kaitannya data analytics yaitu ilmu menganalisis data mentah untuk membuat kesimpulan tentang informasi itu.
Adapun teknik dan proses analitik data ini telah diotomatisasi menjadi proses mekanis dan algoritme yang bekerja pada data mentah untuk konsumsi mahkluk hidup.
Siklus hidup analisis data atau yang disebut dengan istilah data analytics lifecycle ini dirancang khusus untuk masalah big data dan proyek terkait data science.
Mereka (siklus hidup tersebut) memiliki 6 (enam) fase (discovery, data preparation, model plannging, model building, communicate results, operationalize), walaupun dalam pekerjaan proyek mereka dapat terjadi dalam beberapa fase sekaligus.
Untuk sebagian besar fase dalam siklus hidup, gerakannya dapat berupa gerakan maju (forward) atau mundur (backward).
Adapun untuk penggambaran berulang dari siklus hidup ini dimaksudkan untuk lebih dekat menggambarkan proyek nyata, di mana aspek proyek bergerak maju dan dapat kembali ke tahap awal ketika informasi baru ditemukan dan anggota tim belajar lebih banyak tentang berbagai tahap proyek.
Hal ini memungkinkan pesertanya untuk bergerak secara iteratif melalui proses dan mendorong ke arah operasionalisasi pekerjaan proyek.
Contoh dan penerapan dari data analytics ini yakni seperti sebuah perusahaan yang membuat dan menjual produk menelusuri data mereka untuk mempelajari lebih lanjut tentang apa yang dicari pelanggan mereka.
Analisis data memberikan wawasan kepada pengembang produk tentang hal-hal seperti anggaran pelanggan dan fitur yang ingin mereka lihat sebelum melakukan pembelian.
Berdasarkan hal itu, dapat kita lihat bahwa pekerjaan analis data memengaruhi segalanya, mulai dari desain kereta dorong bayi paling trendi tahun depan hingga fitur sedan mewah yang baru.
Apa itu Data, Informasi, dan Pengetahuan?
Menurut situs web wikipedia, data merupakan fakta individu, statistik, atau item informasi, seringkali numerik, yang dikumpulkan melalui observasi.
Data secara teknis adalah sesuatu yang mengacu kepada seperangkat nilai variabel kualitatif atau kuantitatif tentang satu atau lebih orang atau objek, sedangkan datum (data tunggal) adalah nilai tunggal dari variabel tunggal.
Informasi, dalam arti umumnya, informasi merupakan data yang diproses, terorganisir, dan terstruktur. Ini menyediakan konteks untuk mereka (data-data tersebut) dan memungkinkan pengambilan keputusan.
Misalnya, penjualan satu customer atau pembeli di sebuah toko merupakan data, ini pastinya bisa menjadi sebuah informasi ketika sebuah bisnis dapat mengidentifikasi produk apa yang paling diminati atau produk apa saja yang paling tidak diminati.
Secara teknis, informasi dapat dianggap sebagai resolusi dari sebuah ketidakpastian yang menjawab beberapa pertanyaan tentang “apa itu entitas” sehingga itu dapat mendefinisikan esensi dan sifat karakteristiknya.
Selain itu, ada konsep lain yang berkaitan dengan data dan informasi, yaitu adalah knowledge (pengetahuan), ini mengacu pada kemampuan Anda untuk memahami apa yang terjadi di sekitar data dan informasi.
Pengetahuan atau yang dikenal dengan istilah knowledge dalam data science ini merupakan keahlian dan kebijaksanaan Anda untuk menyimpulkan hasil dari data dan informasi yang Anda peroleh.
Pada intinya, sebuah data hanya mengacu pada fakta dan angka mentah, di mana dengan sesuatu yang terbilang sedikit itu tidak dapat memberi tahu Anda apa-apa.
Data diubah menjadi informasi ketika disajikan dalam konteks sehingga dapat menjawab pertanyaan atau mendukung pengambilan keputusan dan ketika informasi ini dapat digabungkan dengan pengetahuan dari seseorang, insight (wawasan) mereka dari pengalaman dan keahlian keputusan yang lebih kuat pun dapat dibuat.
Statistika Deskriptif dalam Data Science
Statistik deskriptif adalah seperangkat metode statistik yang digunakan untuk menggambarkan karakteristik utama data, di mana metode ini bisa berupa grafis atau numerik.
Ada beberapa metode yang tersedia untuk membantu dalam menggambarkan data, masing-masing metode dirancang untuk memberikan insight atau wawasan yang berbeda ke dalam informasi yang tersedia atau hipotesis yang sudah umum.
- Metode grafis; Tujuan utama metode grafis adalah untuk mengatur dan menyajikan data dengan cara manajerial dan tangkas—visualisasi data memainkan peran penting dalam keseluruhan proses ilmu data.
- Penyimpulan data; Statistik deskriptif mengusulkan untuk meringkas dan menunjukkan data sehingga kita dapat dengan cepat mendapatkan gambaran umum dari informasi yang dianalisis dan lebih memahami satu set melalui karakteristik utamanya.
- Langkah-langkah deskriptif utama:
- Nilai representatif: mean dan median
- Dispersi dan variasi: varians dan standar deviasi
- Sifat (bentuk) distribusi: lonceng, seragam, atau asimetris
Oleh karena itu, dengan mengumpulkan data dan menerapkan statistik deskriptif kita dapat mendapatkan nilai yang representatif, mengevaluasi dispersi, dan menilai distribusi data tersebut.
Mean, Modus, Standar Deviasi dalam Statistika
1. Mean
Mean atau rata-rata, secara teori, merupakan jumlah semua elemen himpunan dibagi dengan jumlah elemen dalam himpunan, ini dapat diperlakukan sebagai properti kolaboratif dari seluruh rangkaian nilai.
Kita bisa mendapatkan ide yang cukup bagus tentang seluruh rangkaian data dengan menghitung rata-ratanya. Dengan demikian rumus mean akan menjadi.
Mean = jumlah semua elemen himpunan / jumlah elemen
Pentingnya mean terletak pada kemampuannya untuk meringkas seluruh dataset (kumpulan dari data) dengan nilai tunggal, sebagai contoh misalnya, Anda mungkin ingin membandingkan pendapatan rumah tangga rata-rata kabupaten 1 ke kabupaten 2.
Untuk membandingkan pendapatan rumah tangga antara 2 (dua) kabupaten, Anda tidak dapat membandingkan setiap pendapatan rumah tangga dari satu kabupaten ke kabupaten lainnya, simana solusi terbaik adalah mencari pendapatan rumah tangga rata-rata dari kedua kabupaten dan kemudian membandingkannya satu sama lain.
Dengan membandingkan kedua cara tersebut, kita dapat membuat asumsi tentang kabupaten mana yang lebih makmur dari yang lain.
2. Modus
Modus dalam statistik merupakan nilai yang paling sering muncul dalam kumpulan data.
Seperti mean dan median (untuk mencari nilai tengah), modus juga digunakan untuk meringkas suatu himpunan dengan satu informasi.
Sebagai contoh misalnya, modus dari dataset a = 1,2,3,3,3,3,3,4,4,4,5,5,6,7 adalah 3 karena terjadi jumlah maksimum dalam urutan a.
Sifat penting dari modus adalah bahwa dia sama dengan nilai rata-rata dan median dalam kasus distribusi normal.
Dalam distribusi lain atau distribusi miring nilai modus mungkin berbeda dari keduanya dan dalam distribusi normal, data simetris dengan nilai pusat.
Kurva distribusi normal adalah kurva yang simetris terhadap suatu sumbu.
Sifat penting lainnya dari distribusi normal adalah bahwa setengah dari nilai dalam himpunan lebih besar dari rata-rata dan setengahnya lebih kecil
3. Standar Deviasi
Dalam memahami tentang standar deviasi, kita mungkin ingin mengukur deviasi sekumpulan data dari nilai rata-rata (mean).
Contohnya seperti varian yang sangat besar dari data pendapatan rumah tangga suatu negara dapat diinterpretasikan sebagai ekonomi dengan ketimpangan yang tinggi.
Banyak interpretasi yang berguna dapat dilakukan dengan menganalisis varians dalam data, di mana diperoleh dengan:
- Menemukan perbedaan antara nilai rata-rata dan semua nilai dalam sebuah himpunan.
- Menguadratkan perbedaan itu.
- Menambahkan perbedaan.
Standar deviasi adalah jenis perhitungan statistik yang dihitung dengan akar kuadrat perbedaan data yang memberikan akun yang lebih akurat tentang dispersi nilai dalam kumpulan data.
Karena varians diperoleh dengan mengkuadratkan nilai-nilai, itu tidak dapat diterapkan pada perhitungan dunia nyata.
Standar deviasi dihitung dengan memperoleh akar kuadrat dari varians yang unitnya sama dengan elemen-elemen himpunan.
Maka dari itu, standar deviasi dapat digunakan sebagai besaran statistik terpercaya untuk membuat perhitungan statistik yang tepat.
Deviasi standar juga terkait dengan probabilitas dalam banyak hal, jadi Anda mungkin ingin mengikuti lokakarya tentang probabilitas dan statistik untuk mengeksplorasi lebih banyak tentang hubungan antara kedua topik tersebut.
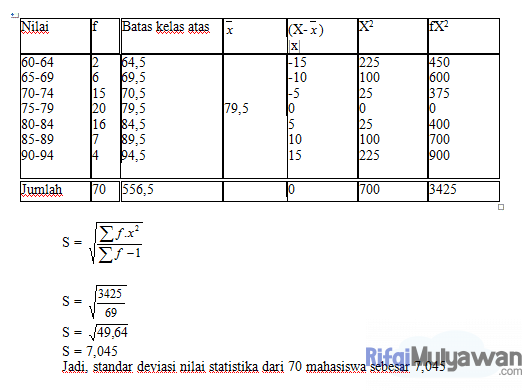
Rumus untuk menghitung standar deviasi:

Penggunaan standar deviasi adalah mencari tahu seberapa besar nilai dataset berbeda dari mean, seperti contoh berikut.
Berikut ini adalah contoh dari data nilai 70 orang mahasiswa data science:
Apa Perbedaan Data Science dengan Artificial Intelligence (AI)?
Kunci perbedaannya secara keseluruhan adalah sebagai berikut:
- Data science adalah proses komprehensif yang melibatkan pra-pemrosesan, analisis, visualisasi, dan prediksi. Di sisi lain, artificial intelligence (AI) adalah implementasi model prediktif untuk meramalkan peristiwa di masa depan.
- Data science terdiri dari berbagai teknik statistik sedangkan AI menggunakan algoritma komputer.
- Alat yang terlibat dalam data science jauh lebih banyak daripada yang digunakan dalam AI. Ini karena ilmu data melibatkan beberapa langkah untuk menganalisis data dan menghasilkan wawasan darinya.
- Data science adalah tentang menemukan pola tersembunyi dalam data. AI adalah tentang memberikan otonomi (sebuah keputusan tanpa gugat) pada model data.
- Dengan data science, kita dapat membangun model yang menggunakan wawasan statistik. Di sisi lain, AI adalah untuk membangun model yang meniru kognisi dan pemahaman manusia.
- Data science tidak melibatkan pemrosesan ilmiah tingkat tinggi dibandingkan dengan ai.
Apa Perbedaan Data Mining dengan Machine Learning?
Penambangan data atau yang dikenal dengan istilah data mining merupakan proses mengekstraksi informasi yang berguna dari sejumlah besar data yang digunakan untuk menemukan pola baru, akurat, dan berguna dalam data, mencari makna dan informasi yang relevan bagi organisasi atau individu yang membutuhkannya.
Sedangkan machine learning atau pembelajaran mesin adalah proses menemukan algoritme yang telah meningkatkan kesopanan pengalaman yang berasal dari data, di mana ini merupakan desain, studi, dan pengembangan algoritme yang memungkinkan mesin belajar tanpa campur tangan manusia.
Ini adalah alat untuk membuat mesin lebih pintar, menghilangkan elemen manusia (tetapi tidak menghilangkan manusia itu sendiri).
Baik data mining (penambangan data) maupun machine learning (pembelajaran mesin) berada di bawah naungan data science, terlebih karena keduanya menggunakan data.
Secara keseluruhan, perbedaan mereka adalah sebagai berikut:
- Usia mereka; Sebagai permulaan, data mining mendahului pembelajaran mesin dua dekade, dengan yang terakhir awalnya disebut penemuan pengetahuan dalam basis data atau knowledge data discovery (KDD). Data mining masih disebut sebagai KDD di beberapa negara termasuk Indonesia. Pembelajaran mesin memulai debutnya dalam program permainan catur. Penambangan data telah ada sejak tahun 1930-an sedangkan pembelajaran mesin muncul pada 1950-an.
- Tujuan mereka; Data mining dirancang untuk mengekstrak aturan dari sejumlah besar data, sementara machine learning mengajarkan komputer cara mempelajari dan memahami parameter yang diberikan.
- Apa yang mereka gunakan; Data mining bergantung pada penyimpanan data yang sangat besar (seperti big data), yang kemudian digunakan untuk membuat perkiraan untuk bisnis dan organisasi lain sedangkan machine learning bekerja dengan algoritme, bukan data mentah.
- Faktor manusia; Inilah merupakan perbedaan yang cukup signifikan, di mana data mining bergantung pada intervensi manusia dan pada akhirnya dibuat untuk digunakan oleh orang-orang. Sedangkan seluruh alasan keberadaan machine learning adalah bahwa dia dapat mengajar sendiri dan tidak bergantung pada pengaruh atau tindakan manusia.
- Hubungannya; Selain itu, data mining adalah proses yang menggabungkan 2 (dua) elemen, yaitu database dan pembelajaran mesin. Yang pertama menyediakan teknik manajemen data, sedangkan yang kedua menyediakan teknik analisis data. Jadi, meskipun data mining membutuhkan machine learning, pembelajaran mesin tidak selalu membutuhkan penambangan data. Walaupun, ada kasus di mana informasi dari data mining digunakan untuk melihat hubungan antar hubungannya. Sulit untuk membuat perbandingannya kecuali kita memiliki setidaknya dua informasi yang membandingkan satu sama lain, sehingga, informasi yang dikumpulkan dan diproses melalui penambangan data kemudian dapat digunakan untuk membantu pembelajaran mesin walaupun itu bukanlah sebuah keharusan.
- Kemampuan berkembangnya; Data mining tidak dapat belajar atau beradaptasi, sedangkan itulah inti dari pembelajaran mesin. Penambangan data hanya mengikuti aturan yang telah ditentukan sebelumnya dan bersifat statis, sementara pembelajaran mesin menyesuaikan algoritme saat keadaan yang tepat terwujud. Penambangan data hanya secerdas pengguna yang memasukkan parameter; pembelajaran mesin berarti komputer itu semakin pintar.
- Bagaimana mereka digunakan; Dalam hal utilitas, setiap proses memiliki spesialisasinya masing-masing. Data mining digunakan di industri ritel untuk memahami kebiasaan membeli pelanggan mereka, sehingga membantu bisnis merumuskan strategi penjualan yang lebih sukses. Sementara itu, perusahaan menggunakan machine learning untuk tujuan seperti mobil self-driving, deteksi kartu kredit, layanan online, intersepsi spam e-mail, intelijen bisnis (misalnya, mengelola transaksi, mengumpulkan hasil penjualan, pemilihan inisiatif bisnis), dan pemasaran yang dipersonalisasi.
Data Science dan Algoritma Klasifikasi
Dalam data science, khususnya klasifikasi, ada variabel kategori target, seperti misalnya braket pendapatan, yang mana itu dapat dipartisi menjadi 3 (tiga) kelas atau kategori, yakni berpenghasilan tinggi, menengah, dan rendah.
Kemudian, model data mining memeriksa satu set besar catatan, masing-masing catatan yang berisi informasi tentang variabel target serta satu set input atau predictor variabel.
Contoh tugas klasifikasi dalam bisnis dan penelitian meliputi:
- Menentukan apakah transaksi kartu kredit tertentu adalah penipuan.
- Menempatkan mahasiswa baru pada jalur tertentu yang berkaitan dengan kebutuhan khusus.
- Menilai apakah aplikasi hipotek adalah risiko kredit yang baik atau buruk.
- Mendiagnosis apakah ada penyakit tertentu.
- Menentukan apakah surat wasiat ditulis oleh almarhum yang sebenarnya, atau dicurangi oleh orang lain.
- Mengidentifikasi apakah perilaku keuangan atau pribadi tertentu menunjukkan kemungkinan ancaman teroris.
Klasifikasi adalah teknik dalam data science atau ilmu data yang digunakan oleh ilmuwan data untuk mengkategorikan data ke dalam sejumlah kelas tertentu.
Teknik ini dapat dilakukan pada data terstruktur (structured) atau tidak terstruktur (unstructured) dan tujuan utamanya adalah untuk mengidentifikasi kategori atau kelas di mana data baru akan masuk.
Teknik ini memiliki algoritma yang dapat digunakan untuk mengaktifkan perangkat lunak analisis teks untuk melakukan tugas-tugas seperti menganalisis sentimen berbasis aspek dan mengkategorikan teks tidak terstruktur berdasarkan topik dan polaritas pendapat.
Ada banyak jenis algoritma klasifikasi yang paling banyak digunakan dalam ilmu data sebagai berikut.
a. K-Nearest Neighbour
Disingkat dengan KNN, K-Nearest Neighbor menjadi salah satu algoritma yang banyak digunakan dalam data mining dan machine learning, ini merupakan jenis dari algoritma klasifikasi di mana pembelajarannya didasarkan pada kesamaan data (vektor) dari yang lain.
Ini juga dapat digunakan untuk menyimpan semua kasus yang tersedia dan mengklasifikasikan kasus baru berdasarkan ukuran kesamaan (misalnya, fungsi jarak).
Contoh algoritma KNN secara sederhana dapat dilihat sebagai berikut:
Mulai dengan mengambil kumpulan data dengan kategori yang diketahui.
Pada langkah awal ini, Anda hanya mengumpulkan data mentah yang tidak disortir. Dalam contoh ini, data secara jelas dikategorikan dengan kelinci dan kura-kura.
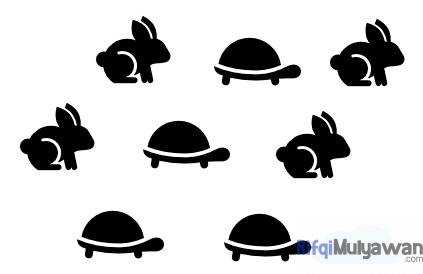
Lakukan clustering, Anda memiliki beberapa pilihan dalam langkah ini dengan berbagai macam dari metode clustering.

Lanjutkan dengan menambahkan sel dengan kategori yang tidak diketahui seperti gambar di bawah ini:

Jika sudah, maka temukanlah “K”.
Mungkin langkah yang paling menantang adalah menemukan K yang “tepat”.
Perlu untuk diketahui bahwa akar kuadrat dari n (jumlah item dalam kumpulan data) adalah tempat yang mudah untuk memulainya.
(n)
= (8)
= 2.82
= 3
Meskipun akar kuadrat dari n sederhana, itu bukan metode yang paling akurat.
Idealnya Anda harus menggunakan set pelatihan (yaitu set yang dikategorikan dengan baik) untuk menemukan “K” yang berfungsi untuk data Anda.
Hapus beberapa titik data yang dikategorikan dan jadikan mereka sebagai “tidak diketahui”, uji beberapa nilai untuk K tersebut untuk melihat apa yang berhasil.
Seringkali, metode elbow dapat bekerja dengan baik, di mana Anda menemukan K optimal berdasarkan tingkat kesalahan terendah.
Jia sudah, lalu cari “K” nearest neighbour-nya, untuk contoh ini, kita dapat menggunakan visual untuk mencari tetangga terdekatnya.

Langkah terakhirnya yaitu dengan mengklasifikasikan titik baru, titik atau poin baru diklasifikasikan berdasarkan suara terbanyak.
Jika sebagian besar tetangga Anda adalah penyu, kemungkinan besar Anda juga penyu.
Dalam hal ini, dua dari tiga tetangga yang tidak diketahui adalah kelinci sehingga poin baru diklasifikasikan sebagai kelinci.

b. Algrotima C4.5
Algoritma C4.5 sering digunakan dalam data mining sebagai pengklasifikasi pohon keputusan atau yang lebih dikenal dengan istilah decision tree yang dapat digunakan untuk menghasilkan keputusan, berdasarkan sampel data tertentu (prediktor univariat atau multivariat).
Algoritma decision tree termasuk dalam algoritma pembelajaran yang terawasi. Algoritma ini dapat digunakan untuk menyelesaikan regresi dan masalah klasifikasi lainnya.
Pohon keputusan membangun model klasifikasi atau regresi dalam bentuk struktur pohon yang memecah dataset menjadi subset yang lebih kecil dan lebih kecil sementara pada saat yang sama pohon keputusan terkait dikembangkan secara bertahap.
Tujuan penggunaan algoritma pohon keputusan adalah untuk memprediksi kelas atau nilai variabel target dengan mempelajari aturan keputusan sederhana yang disimpulkan dari data sebelumnya.
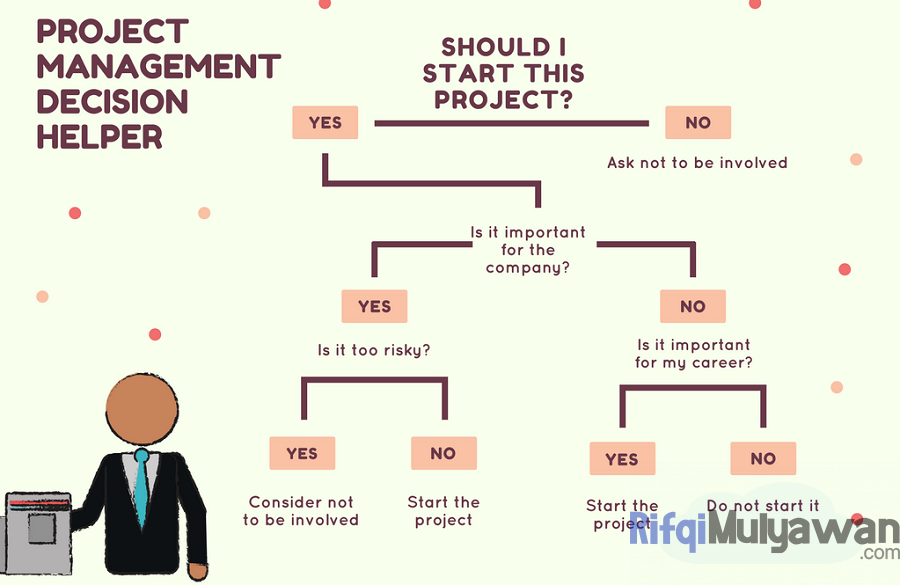
Contohnya secara sederhana, dapat kita bayangkan jika seseorang adalah seorang manajer proyek dan kita perlu memutuskan apakah akan memulai proyek tertentu atau tidak.
Dalam hal ini, kita perlu mempertimbangkan kemungkinan hasil dan konsekuensi yang penting, sebagaimana diagram di bawah ini.
c. Naive Bayes
Naive bayes adalah teknik klasifikasi berdasarkan teorema seorang ahli yang bernama bayes dengan asumsi independensi antar prediktor.
Secara sederhana, classifier atau pengklasifikasi naive bayes mengasumsikan bahwa keberadaan fitur tertentu dalam suatu kelas tidak terkait dengan keberadaan fitur lainnya.
Classifier mengasumsikan bahwa kehadiran fitur tertentu di kelas tidak terkait dengan kehadiran fitur lainnya, di mana ini memperbarui pengetahuan langkah demi langkah dengan informasi baru.
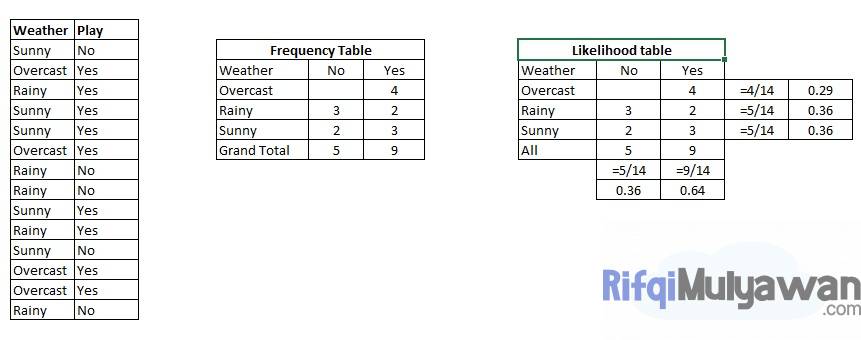
Untuk contohnya, berikut adalah kumpulan data pelatihan cuaca dan variable “Play” target yang sesuai (menunjukkan kemungkinan bermain).
Sekarang, kita perlu mengklasifikasikan apakah pemain akan bermain atau tidak berdasarkan kondisi cuaca.
Langkah pertama, ubahlah kumpulan data menjadi tabel frekuensi.
Langkah berikutnya, kita lanjutkan dengan memuat tabel Likelihood dengan mencari probabilitas seperti Probabilitas mendung = 0,29 dan probabilitas bermain adalah 0,64.
Sekarang, mari kita gunakan persamaan Naive Bayes untuk menghitung probabilitas posterior untuk setiap kelasnya, di mana kelas dengan probabilitas posterior tertinggi adalah hasil prediksinya.
Disini masalahnya, pemain akan bermain jika cuaca cerah.
Lalu, apakah pernyataan ini benar?
Kita dapat menyelesaikannya dengan menggunakan metode probabilitas posterior yang dibahas di atas.
P(Yes | Sunny) = P( Sunny | Yes) * P(Yes) / P (Sunny)
Di sini kita memiliki P (Sunny |Yes) = 3/9 = 0.33, P(Sunny) = 5/14 = 0.36, P( Yes)= 9/14 = 0.64.
Sekarang, P (Yes | Sunny) = 0.33 * 0.64 / 0.36 = 0.60, yang artinya probabilitas yang lebih tinggi.
Naive Bayes menggunakan metode serupa untuk memprediksi probabilitas kelas yang berbeda berdasarkan berbagai atribut.
Algoritma ini banyak digunakan dalam klasifikasi teks dan dengan masalah memiliki banyak kelas.
d. Jaringan Syaraf Tiruan
Jaringan syaraf tiruan dalam ilmu data dikenal dengan istilah neural network, ini adalah serangkaian algoritma yang mencoba mengidentifikasi hubungan yang mendasarinya dalam kumpulan data melalui proses yang meniru cara kerja otak manusia.
Dalam data science, jaringan saraf membantu mengelompokkan dan mengklasifikasikan hubungan yang kompleks.
Jaringan saraf dapat digunakan untuk mengelompokkan data yang tidak berlabel menurut kesamaan di antara input contoh dan mengklasifikasikan data ketika mereka memiliki kumpulan data berlabel untuk dilatih.
Terkait hal contohnya, beberapa ahli menjelaskannya dengan konsep fungsi kerugian (loss function).
Sebuah jaringan saraf mengasah pada jawaban yang benar untuk suatu masalah dengan meminimalkan fungsi kerugian (loss function) tersebut.
Misalkan kita memiliki persamaan linier sederhana seperti y = mx + b, di mana ini memprediksi beberapa nilai y yang diberikan nilai x.
Model prediktif tidak selalu 100% benar, ukuran seberapa salah itu adalah kerugiannya.
Tujuan dari pembelajaran mesin itu untuk mengambil satu set pelatihan untuk meminimalkan fungsi kerugian. Itu benar dengan regresi linier, jaringan saraf, dan algoritma ML lainnya.
Sebagai contoh, misalkan m = 2, x = 3, dan b = 2.
Maka nilai prediksi kita dari y = 2 * 3 + 2 = 8.
Tetapi nilai pengamatan aktual kita adalah 10, jadi kerugiannya adalah 10 – 8 = 2.
Deep Learning dan Data Science
Pembelajaran mendalam atau deep learning adalah teknik machine learning yang mengajarkan komputer untuk melakukan apa yang terjadi secara alami pada manusia dengan konsep belajar dengan memberi contoh.
Pembelajaran mendalam adalah teknologi utama di balik mobil tanpa pengemudi, memungkinkan mereka mengenali tAnda berhenti, atau membedakan pejalan kaki dari tiang lampu.
Ini adalah kunci untuk kontrol suara di perangkat konsumen seperti ponsel, tablet, tv, dan speaker handsfree.
Pembelajaran mendalam mendapatkan banyak perhatian akhir-akhir ini dan untuk alasan yang bagus. Ini mencapai hasil yang tidak mungkin dilakukan sebelumnya.
Dalam deep learning, model komputer belajar untuk melakukan tugas klasifikasi langsung dari gambar, teks, atau suara.
Model pembelajaran mendalam dapat mencapai akurasi mutakhir, terkadang melebihi kinerja tingkat manusia. Model dilatih dengan menggunakan sekumpulan besar data berlabel dan arsitektur jaringan saraf yang berisi banyak lapisan.
Beberapa contohnya termasuk seperti alat mengemudi otomatis, di sini peneliti otomotif menggunakan pembelajaran mendalam untuk secara otomatis mendeteksi objek seperti rambu berhenti dan lampu lalu lintas.
Selain itu, pembelajaran mendalam digunakan untuk mendeteksi pejalan kaki, yang membantu mengurangi kecelakaan.
Contoh lainnya seperti dalam penelitian medis, di mana para peneliti kanker menggunakan pembelajaran mendalam untuk mendeteksi sel kanker secara otomatis.
Seperti Tim di UCLA yang membuat mikroskop canggih yang menghasilkan kumpulan data berdimensi tinggi yang digunakan untuk melatih aplikasi pembelajaran mendalam guna mengidentifikasi sel kanker secara akurat.
Metode Regresi dan Regresi Linier
Juga dikenal dengan regression analysis, metode regresi adalah metode statistik yang membantu kita untuk menganalisis dan memahami hubungan antara 2 (dua) atau lebih variabel yang diminati.
Proses yang disesuaikan untuk melakukan analisis regresi membantu untuk memahami faktor mana yang penting, faktor mana yang dapat diabaikan, dan bagaimana faktor tersebut saling mempengaruhi.
Agar analisis regresi menjadi metode yang berhasil, maka kita perlu memahami istilah-istilah berikut:
- Dependent variable; Ini adalah variabel yang kita coba pahami atau ramalkan.
- Independent variable; ini adalah faktor-faktor yang mempengaruhi analisis atau variabel target dan memberi kita informasi mengenai hubungan variabel dengan variabel target.
Adapun hal yang paling sederhana dari semua jenis regresi adalah regresi linier di mana ia mencoba membangun hubungan antara variabel independen dan dependen.
Variabel dependen yang dipertimbangkan di sini selalu merupakan variabel kontinu, di mana regresi linier adalah model prediksi yang digunakan untuk mencari hubungan linier antara variabel terikat dan satu atau lebih variabel bebas.
Regresi linier sederhana adalah seperti:
X —–> Y
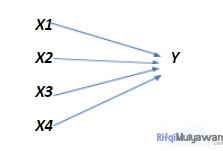
Jika hubungan antara variabel Independen dan variabel dependen berjumlah kelipatan, maka disebut regresi linier berganda, seperti gambar berikut:
Algoritma Clustering dan K-Means Clustering
Clustering adalah teknik machine learning yang melibatkan pengelompokan titik data.
Mengingat satu set titik data, kita dapat menggunakan algoritma pengelompokan untuk mengklasifikasikan setiap titik data ke dalam kelompok tertentu.
Secara teori, titik data yang berada dalam kelompok yang sama harus memiliki sifat atau fitur yang serupa, sedangkan titik data dalam kelompok yang berbeda harus memiliki sifat atau fitur yang sangat berbeda.
Clustering adalah metode pembelajaran tanpa pengawasan dan merupakan teknik umum untuk analisis data statistik yang digunakan di banyak bidang.
Dalam data science, kita dapat menggunakan analisis pengelompokan untuk mendapatkan beberapa wawasan berharga dari data kita dengan melihat kelompok mana yang menjadi titik data saat kita menerapkan algoritme pengelompokan.
K-means mungkin adalah algoritma pengelompokan yang paling terkenal yang diajarkan di banyak kelas pengantar ilmu data dan pembelajaran mesin.
Algoritme kmeans adalah algoritme iteratif yang mencoba mempartisi kumpulan data ke dalam subkelompok (cluster) berbeda yang tidak tumpang tindih yang telah ditentukan sebelumnya di mana setiap titik data hanya dimiliki oleh satu kelompok
K-means clustering adalah salah satu algoritma clustering yang paling populer dan biasanya hal pertama yang diterapkan praktisi ketika menyelesaikan tugas clustering untuk mendapatkan gambaran tentang struktur dataset.
Tujuan k-means adalah mengelompokkan titik data ke dalam subkelompok berbeda yang tidak tumpang tindih.
Itu melakukan pekerjaan yang sangat baik ketika cluster memiliki semacam bentuk bola. Namun, ia menderita karena bentuk geometris cluster menyimpang dari bentuk bola.
Selain itu, dia juga tidak mempelajari jumlah cluster dari data dan mengharuskannya untuk ditentukan sebelumnya.
K-means clustering mencoba mengelompokkan item yang sejenis dalam bentuk cluster. Ini menemukan kesamaan antara item dan mengelompokkannya ke dalam cluster.
Algoritma pengelompokan K-means bekerja dalam 3 (tiga) langkah, mari kita lihat apa saja tiga langkah ini.
- Pilih nilai k.
- Inisialisasi centroid.
- Pilih grup dan temukan rata-ratanya.
Mari kita pahami langkah-langkah di atas dengan bantuan gambar di bawah ini:
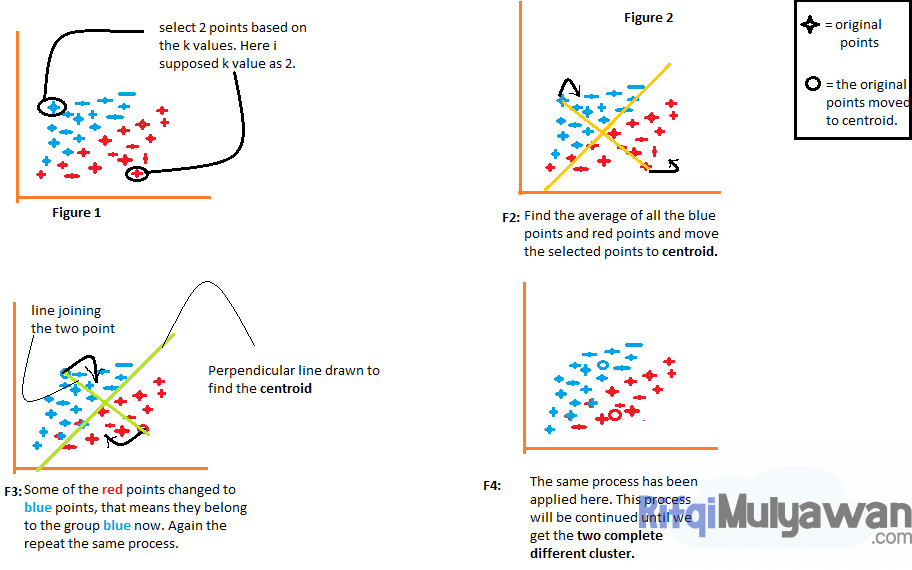
Mari kita pahami setiap gambarnya satu per satu.
Gambar 1 menunjukkan representasi data dari 2 (dua) item yang berbeda, di mana item pertama ditampilkan dengan warna biru dan item kedua ditampilkan dengan warna merah.
Di sini kita pilih nilai k secara acak yaitu 2, perlu diketahui juga bahwa ada beberapa metode berbeda yang dengannya kita dapat memilih nilai k yang tepat.
Pada gambar 2, kita gabungkan dua titik yang dipilih untuk mengetahui centroid (titik tengah objek), maka kita akan menggambar garis tegak lurus terhadap garis tersebut.
Dengan begitu, titik-titik tersebut akan pindah ke centroid mereka, jika Anda akan melihat di sana, maka Anda akan melihat bahwa beberapa titik merah sekarang dipindahkan ke titik biru.
Sekarang, titik-titik ini termasuk dalam kelompok item warna biru, proses yang sama akan berlanjut pada gambar 3, di mana kita akan menggabungkan dua titik dan menggambar garis tegak lurus dengan itu dan mencari pusat massa.
Sekarang dua titik akan pindah ke pusatnya dan lagi beberapa titik merah diubah menjadi titik biru.
Proses yang sama terjadi pada gambar 4, di mana proses ini akan dilanjutkan sampai dan kecuali kita mendapatkan dua kelompok yang sama sekali berbeda dari kelompok-kelompok ini.
Perlu diketahui bahwa pengelompokan K-means menggunakan metode jarak euclidean untuk mengetahui jarak antar titik.
Algoritma Association Rule dan Apriori
Association rule adalah metode machine learning berbasis aturan untuk menemukan hubungan menarik antara variabel dalam database besar, di mana ini mengidentifikasi asosiasi if-then yang sering disebut aturan asosiasi yang terdiri dari anteseden (jika) dan konsekuen (maka).
Ada tiga metrik umum untuk mengukur asosiasi, yaitu:
1. Support
Support adalah indikasi seberapa sering item muncul dalam data. Secara matematis, dukungan adalah bagian dari jumlah total transaksi di mana set item terjadi.
Rumusnya:
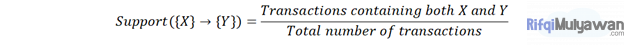
2. Confidence
Confidence menunjukkan berapa kali pernyataan if-then ditemukan benar. Keyakinan adalah probabilitas bersyarat terjadinya konsekuen diberikan anteseden.
Rumusnya:

3. Lift
Lift dapat digunakan untuk membandingkan keyakinan dengan keyakinan yang diharapkan. Ini menunjukkan seberapa besar kemungkinan item y dibeli saat item x dibeli, sambil mengontrol seberapa populer item y.
Rumusnya:
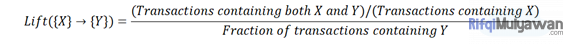
Kemudian ada juga algoritma apriori, di mana ini merupakan algoritma populer untuk mengekstraksi frequent (yang sering) itemset.
Apriori adalah algoritme untuk penambangan kumpulan item yang sering dan pembelajaran aturan asosiasi melalui basis data relasional yang berlanjut dengan mengidentifikasi item individu yang sering dalam database dan memperluasnya ke set item yang lebih besar dan lebih besar selama set item tersebut muncul cukup sering dalam database.
Algoritma Apriori menyatakan bahwa setiap subset dari kumpulan item yang sering juga harus sering.
Sebaliknya, jika suatu itemset jarang maka semua supersetnya harus jarang terjadi. Dengan kata lain, tidak ada set super dari set item yang jarang harus dibuat atau diuji.
Sederhanyanya, algoritma Apriori ini dapat dikatakan sebagai algoritma yang efisien Ketika menentukan jumlah itemset frequent.
Contohnya jika itemset x tidak frequent (dalam artian mereka munculnya tidak sering dalam suatu transaksi), maka item apapapun yang dikombinasikan pada itemset x tidak akan membuatnya menjadi frequent.
Inilah yang dimanfaatkan oleh jenis algoritma ini, yakni untuk mempersempit (mengurangi) spasi pencarian kandidat itemset yang frequent yang ditandai dengan pembatasan pada nilai puncak batas nilai support (minSupport).
Sebagai contoh, kita mulai dengan menentukan nilai minimum support untuk transaksi:

Semisal untuk nilai minimum support yang akan kita masukkan yaitu 4, di mana ini setara dengan 4/8 = 0,5 (50%).
Jadi, untuk iterasi pertama k-itemset atau k=1 aturannya yaitu:
Beras = 6
Buku=4
Minyak=6
Telur=6Topi=3
Untuk 5 itemset di atas, item topi (3/8 = 0,375 atau 37,5%) tidak dapat mematuhi nilai minimum support yaitu 50%, maka pada iterasi ke-2 (dua) k-itemset (k=2), semua itemset yang mengandung topi tentunya akan dieliminasi.
Beras,Buku} = 2{Beras,Telur}=5{Beras,Topi}=2{Buku,Minyak}=3{Buku,Telur}=2{Buku,Topi}=1{Telur,Minyak}=5{Minyak,Topi}=3{Telur,Topi}=3Dan seterusnya…
Lanjut, pada k-itemset di atas, itemset beras dan buku yaitu 2/8 atau 0,25 (25%), untuk buku, minyak yaitu 3/8 atau 0.375 (37.5%) dan buku, telur yaitu 2/8 (25%) tidak dapat memenuhi nilai minimum support.
Maka, itemset tersebut pun juga harus dieliminasi.
Lalu, untuk iterasi ketiga k-itemset (k=3), di mana hanya tersisa 1 itemset saja yang memenuhi minimum nilai support yaitu adalah itemset telur, minyak, beras yang memiliki nilai 4/8 atau 0.5 (50%).
{Telur,Minyak,Beras}=4
{Telur,Minyak,Buku}=2
{Telur,Minyak,Topi}=2
{Telur,Beras,Buku}=1
{Telur,Beras,Topi}=2
{Beras,Buku,Topi}=0
{Beras,Topi,Minyak}=2
{Beras,Buku,Minyak,}=1
{Buku,Minyak,Topi}=1
Dan seterusnya…
Maka, dengan algoritma Apriori, aturan asosiasi (association rule) yang sudah kita dapatkan yaitu:
- {Beras,Minyak} dengan nilai confident, c(Beras->Minyak) = 4/6 = 0.67 (67%).
- {Beras,Telur} dengan Nilai confident, c(Beras->Telur) = 5/6 = 0.83 (83%).
- {Minyak,Telur} dengan Nilai confident, c(Minyak->Telur) = 5/6 = 0.83 (83%).
- {Telur,Minyak,Beras} dengan Nilai confident, c(Telur,Minyak->Beras) = 4/6 = 0.67 (67%).
Jadi, aturan asosiasi atau association rule-nya adalah:
- If Beras, maka Minyak.
- If Beras, maka Telur.
- If Minyak, maka telur.
- If Telur dan Minyak, maka Beras.
Daftar Pustaka
- Discovering Knowledge in Data : An Introduction to Data Mining; 2005; Daniel T. Larose; Wiley
- Algoritma Data Mining;, 2009, Kusrini dan Emha Taufiq Luthfi, Andi Offset
- Data Science & Big Data Analytics: Discovering, Analyzing, Visualizing and Presenting Data; 2015; EMC Education Services; John Wiley & Sons, Inc
- Prasetyo, E. (2012). Data Mining konsep dan Aplikasi menggunakan MATLAB. Yogyakarta: Andi.
- Larose, D. T. (2015). Data mining and predictive analytics. John Wiley & Sons.
- Nama Web, “.” Diakses pada September 07, 2021. url.
- IBM. “Business Analytics.” Diakses pada September 07, 2021. https://www.ibm.com/analytics/business-analytics.
- Investopedia. “Data Analytics.” Diakses pada September 07, 2021. https://www.investopedia.com/terms/d/data-analytics.asp.
- Wikipedia. “Data.” Diakses pada September 07, 2021. https://en.wikipedia.org/wiki/data.
- Wikipedia. “Information.” Diakses pada September 07, 2021. https://en.wikipedia.org/wiki/information.
- PPC Expo. “Data vs Information vs Knowledge.” Diakses pada September 07, 2021. https://ppcexpo.com/blog/data-vs-information-vs-knowledge.
- Lumen Learning. “Data Information and Knowledge.” Diakses pada September 07, 2021. https://courses.lumenlearning.com/santaana-informationsystems/chapter/data-information-and-knowledge/.
- A. Leonardo. “Descriptive Statistics in Data Science.” Diakses pada September 07, 2021. https://www.linkedin.com/pulse/statistical-data-analysis-fundamental-tools-techniques-leonardo-a/?published=t.
- Udemy. “Statistics Formula.” Diakses pada September 07, 2021. https://blog.udemy.com/statistics-formula/.
- Dosen Pendidikan. “Rumus Standar Deviasi.” Diakses pada September 09, 2021. https://www.dosenpendidikan.co.id/rumus-standar-deviasi/.
- Data Flair Training. “Data Science vs Artificial Intelligence.” Diakses pada September 09, 2021. https://data-flair.training/blogs/data-science-vs-artificial-intelligence/.
- Simpli Learn. “Data Mining vs Machine Learning.” Diakses pada September 09, 2021. https://www.simplilearn.com/data-mining-vs-machine-learning-article.
- Intell Spot. “Example of Decision Tree.” Diakses pada September 09, 2021. https://www.intellspot.com/decision-tree-examples/.
- Analytics Vidhya. “Naïve Bayes Explained.” Diakses pada September 09, 2021. https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/.
- Multi Matics. “5 Types of Classification Algorithms in Data Science.” Diakses pada September 09, 2021. https://multimatics.co.id/blog/jun/5-types-of-classification-algorithms-in-data-science.aspx.
- BMC. “Introduction to Neural Network.” Diakses pada September 10, 2021. https://www.bmc.com/blogs/neural-network-introduction/.
- Math Works. “Deep Learning.” Diakses pada September 10, 2021. https://www.mathworks.com/discovery/deep-learning.html.
- My Great Learning. “What is Regression.” Diakses pada September 10, 2021. https://www.mygreatlearning.com/blog/what-is-regression/.
- Towards Data Science. “The 5 Clustering Algorithms Data Scientists Need to Know.” Diakses pada September 11, 2021. https://towardsdatascience.com/k-means-clustering-algorithm-applications-evaluation-methods-and-drawbacks-aa03e644b48a.
- Towards Data Science. “K-Means Clusterring Algorithm Applications, Evaluation Methods and Drawbacks.” Diakses pada September 10, 2021. https://towardsdatascience.com/k-means-clustering-algorithm-applications-evaluation-methods-and-drawbacks-aa03e644b48a.
- Yosola, Adekanmbi. “Association Rule Mining – Apriori Algorithm.” Diakses pada September 12, 2021. https://medium.com/@adekanmbi.yosola/association-rule-mining-apriori-algorithm-c517f8d7c54c.
- Glen, Stephanie. “K-NN (k-Nearest Neighbor): Overview, Simple Example” From StatisticsHowTo.com: Elementary Statistics for the rest of us! https://www.statisticshowto.com/k-nn-k-nearest-neighbor/
Kesimpulan
Oke, di atas adalah Makalah tentang Data Science, Ringkasan, Teori, Contoh Kasus, Perhitungan, Lengkap + Link Downloadnya dari berbagai sumber.
Seperti yang dapat kalian lihat di atas, ilmu data secara luasnya merupakan bidang studi tentang data.
Kalian tentunya dapat menggunakan makalah ini untuk keperluan belajar-mengajar kalian di sekolah, kampus atau universitas.
Terkait pembahasan ini, jika kalian ingin lebih mempelajari mengenai data science, saran Kami pribadi kalian perlu mengunjungi Situs Towards Data Science.
Bagi kalian yang memerlukan file mentah makalah tentang data science (original) tanpa gaya bahasa yang sudah disesuaikan dengan website Kami, berupa format dokumen Ms. Office Word, silahkan kalian download tanpa perlu copy-paste dengan menggunakan tombol di bawah ini:
Penutup
Demikianlah postingan artikel yang dapat Kami bagikan kali ini tentang Makalah tentang Data Science, Ringkasan, Teori, Contoh Kasus, Perhitungan, Lengkap + Link Downloadnya.
Semoga apa yang sudah Kami coba sampaikan serta jelaskan di sini dapat bermanfaat dan juga dapat menambah wawasan dan pengetahuan kita semua terutama dalam bidang teknologi dan bisnis serta pengetahuan.
Silahkan bagikan artikel atau postingan Kami di sini kepada teman, kerabat serta rekan kerja dan bisnis kalian semua khususnya jika kalian temukan ini bermanfaat dan juga jangan lupa subscribe Blog dan YouTube Kami. Sekian dari Kami, Terima Kasih.
Postingan ini juga tersedia dalam versi:






 di HP/Smartphone/Mobile: Pengertian, Jenis, Macam-Macam Peran, Tantangan, serta Masa Depan Implementasi dan Inovasinya!")

